Como Criar um Banco de Dados SQL através de uma API utilizando Python
Postado originalmente em 8 de dezembro de 2021

Muitas pessoas se interessam pela área de dados pois ouvem falar sobre tecnologias extraordinárias que fazem coisas incríveis. Carros que dirigem sozinhos, máquinas que ganham de qualquer ser humano em xadrez, algoritmos que descobrem quando e como você sentirá vontade de comprar um produto… Enfim, a lista é longa. Porém, nada disso seria possível sem um banco de dados adequado. Um banco de dados é uma coleção de dados organizados e armazenados de forma estruturada. É através de um banco de dados que métodos de Machine Learning e Inteligência Artificial podem acessar os dados e aprender com eles.
Mas como criar um banco de dados? Neste tutorial, você irá aprender como criar um simples banco de dados no formato SQL, com dados requisitados via uma API e utilizando a linguagem Python. Caso queira checar o notebook com todo o código do tutorial, clique aqui.
Importando dados da API
Para este tutorial, vamos utilizar a API de dados abertos da Câmara dos Deputados do Brasil. Você pode conferir a documentação da API neste link.
Após importar o método get da biblioteca requests, e a biblioteca pandas a fim de utilizarmos um DataFrame, vamos tomar os dados através da API:
# Importar bibliotecas
from requests import get
import pandas as pd# Criar DataFrame com dados da API
df = pd.DataFrame(get("https://dadosabertos.camara.leg.br/api/v2/deputados").json()['dados'])
df.head()
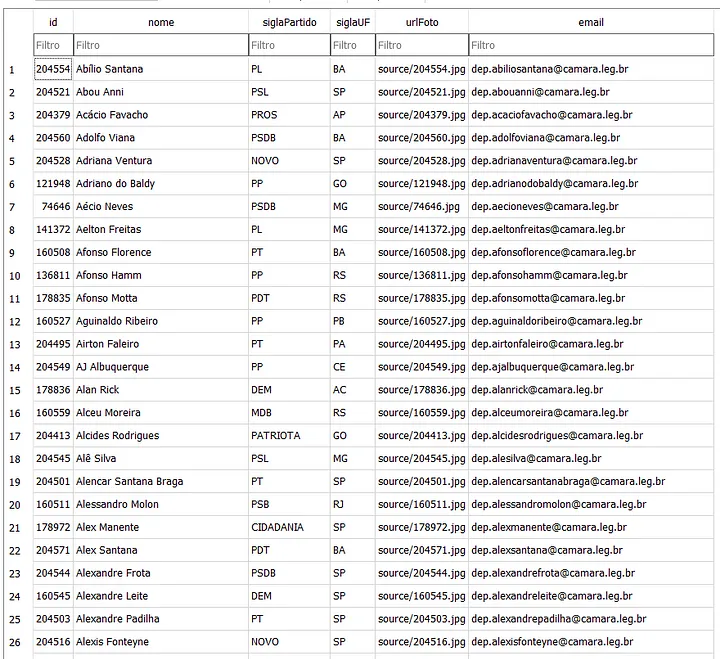
Esta tabela possui algumas informações básicas sobre todos os 513 deputados ativos da Câmara, sendo que cada deputado representa uma linha da tabela. Vamos utilizar estes dados para inserir em um banco SQL.
Nem todas as informações deste DataFrame são relevantes. Vamos deletar algumas colunas, nomeadamente uri, uriPartido, e idLegislatura.
df.drop("uri", axis=1, inplace=True)
df.drop("uriPartido", axis=1, inplace=True)
df.drop("idLegislatura", axis=1, inplace=True)Muitas vezes, manter imagens em um servidor externo, o qual não temos controle, pode diminuir a velocidade de nossas aplicações, caso queiramos renderizar a imagem em um app ou website, por exemplo. Por isso, vamos baixar as imagens de cada deputado utilizando de novo o método get, guardá-las em uma pasta chamada source, e substituir os links em urlFoto por links na nossa pasta local.
# Criar pasta source caso ela não exista
import os
if not os.path.exists("source"):
os.makedirs("source")# Iterar cada url, baixando cada imagem
for url in df["urlFoto"]:
photo_name = url.split("/")[-1]
img_data = get(url).content
with open("source/"+photo_name, 'wb') as handler:
handler.write(img_data)# Substituir URLs
df["urlFoto"] = ["source/"+i.split("/")[-1] for i in df["urlFoto"]]
df.head()Com estas pequenas transformações nos nossos dados, temos agora informações estruturadas para inserir em um banco de dados SQL.

Inserindo os dados em um banco de dados SQLite
Para inserir a tabela em um pequeno banco de dados, iremos utilizar a biblioteca SQLite3 do Python. O SQLite é um banco de dados relacional escrito em C, criado especificamente para bancos de dados pequenos, que podem rodar fora de um servidor padrão, e geralmente são utilizados diretamente em aplicações.
Para rodar o SQLite3 no Python, precisamos de um conector e um cursor. O conector irá gerar uma sessão em nosso database, e criar um arquivo para ele caso não exista. Neste exemplo, vamos criar um banco de dados chamado deputadosDB.db. Já o cursor será uma instância através da qual nosso programa Python irá gerar cláusulas SQL e rodá-las no banco de dados.
import sqlite3
connector = sqlite3.connect('deputadosDB.db')
cursor = connector.cursor()Agora, podemos criar uma tabela no nosso banco de dados através de uma cláusula SQL. Vamos criar uma tabela chamada deputados e adicionar todas as colunas que estão presentes em nosso DataFrame.
cursor.execute("CREATE TABLE IF NOT EXISTS deputados (id int not null primary key, nome varchar(99), siglaPartido varchar(99), siglaUF varchar(2), urlFoto varchar(50), email varchar(199))")Temos nossa tabela. Agora precisamos inserir dados nela. Para isso, vamos iterar nosso DataFrame e, a cada iteração, adicionaremos os dados no nosso banco de dados.
for row in df.iterrows():
cursor.execute("INSERT INTO deputados (id, nome, siglaPartido, siglaUF, urlFoto, email) VALUES ({})".format(','.join(['?']*len(df.columns))), tuple(row[1]))Aqui, a cada iteração rodamos uma execução SQL para inserir os dados nas colunas especificadas. Ao invés de escrever os valores, usamos um placeholder para preencher os dados referentes a cada linha iterada. O .format(‘, ‘.join([‘?’]*len(df.columns)) irá preencher o placeholder {} com pontos de interrogação separados por vírgulas. O ponto de interrogação é um “coringa” em SQL, e os dados passados estão em tuple(row[1]).
A partir de agora, tudo que precisamos fazer é dar um commit em nossas alterações para escrever elas no banco de dados deputadosDB.db.
connector.commit()E pronto! Com um programa como o DB Browser, é possível verificar como ficou nosso banco de dados: